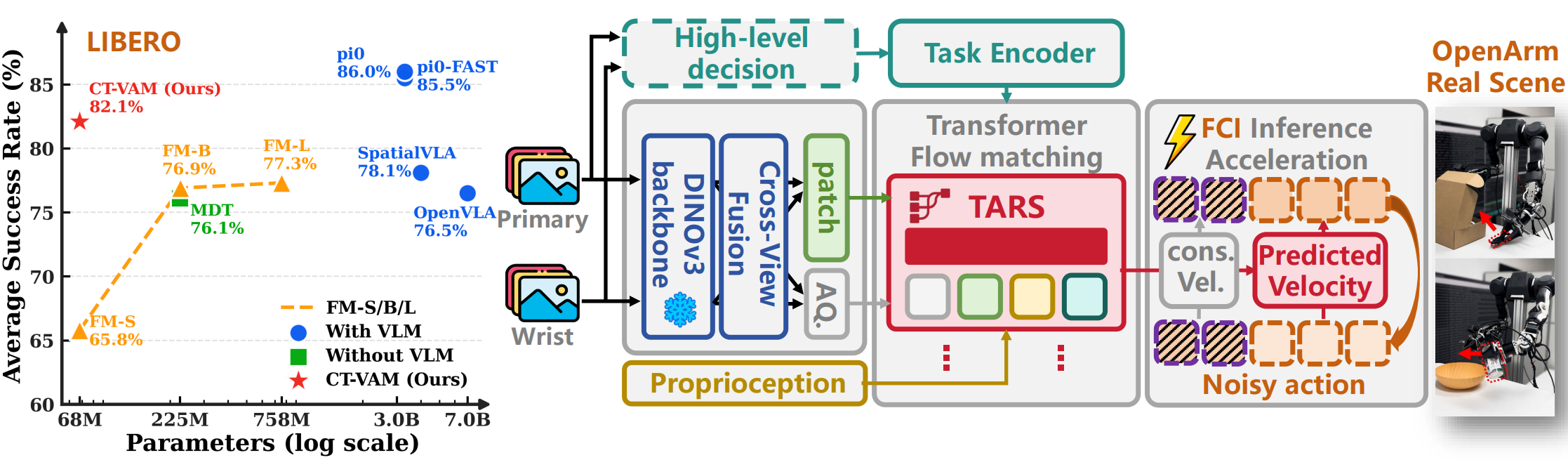
Overview of CT-VAM: parameter--performance comparison on LIBERO, CT-VAM architecture, and real-world deployment. The dashed high-level decision module indicates a compatible upstream module for future integration, but it is not introduced or evaluated in this work.
Abstract
Vision-language-action models have shown strong promise for robot manipulation, yet raw language is primarily needed to specify task intent rather than to be repeatedly processed during high-frequency low-level execution. Motivated by this separation, we propose a cerebello-thalamic-inspired vision-action model (CT-VAM) for efficient task-conditioned visuomotor control. CT-VAM acts as a compact local execution policy that predicts action chunks from dual-view visual observations, proprioception, and a lightweight task condition, potentially enabling a practical cloud-edge paradigm in which high-level semantic reasoning can be handled by large models while fast closed-loop control runs on local hardware. To fuse heterogeneous inputs effectively, CT-VAM introduces TARS (Thalamic Action Routing Stream), a stream-separated conditional attention decoder that independently routes action, visual and task streams, preventing dense sensory tokens from overwhelming compact task-relevant conditions. With only 68M parameters, CT-VAM achieves LIBERO success rates competitive with substantially larger VLA models, while reducing inference latency. Together with flow-consistent inpainting for asynchronous chunk execution, CT-VAM supports high-frequency control and demonstrates robust real-world deployment on resource-constrained robotic platforms.
Highlights
Grounded visuomotor execution
CT-VAM separates semantic language grounding from high-frequency visual feedback control. Raw language is converted into an intent representation, while the low-level policy uses visual-proprioceptive observations for closed-loop action generation.
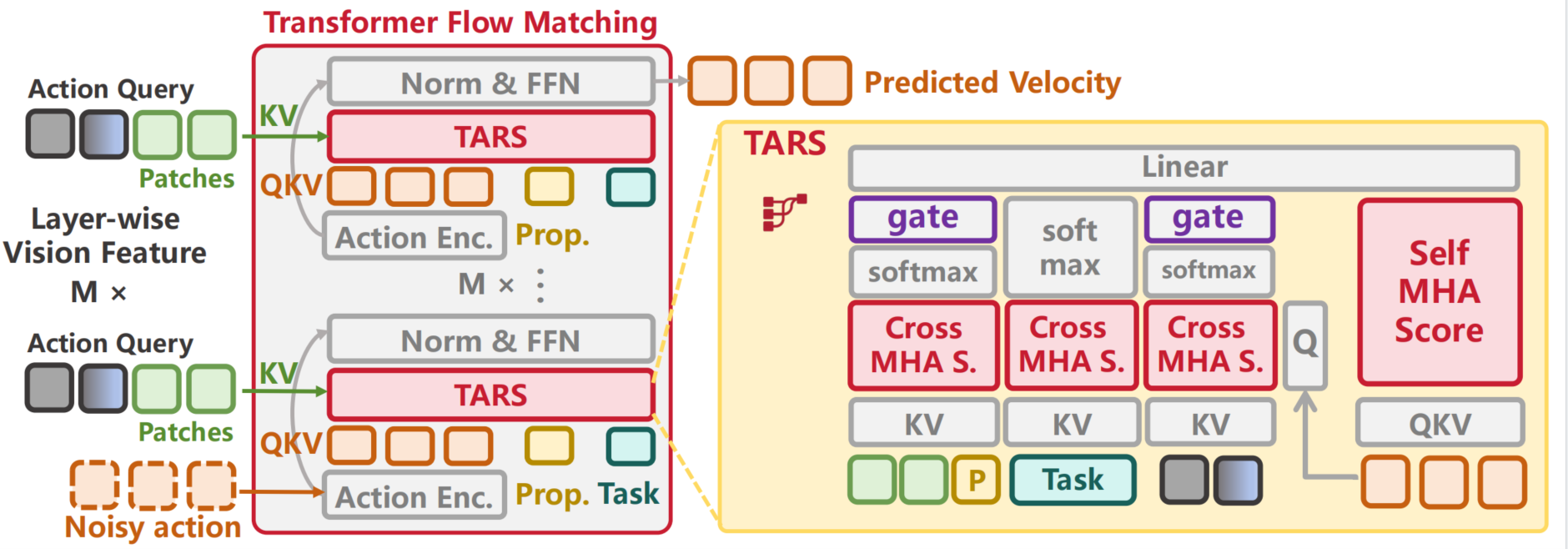
TARS
TARS is a stream-separated conditional attention module that routes and gates action, visual, proprioceptive, and task streams, preventing dense visual tokens from overwhelming compact but task-relevant conditions.
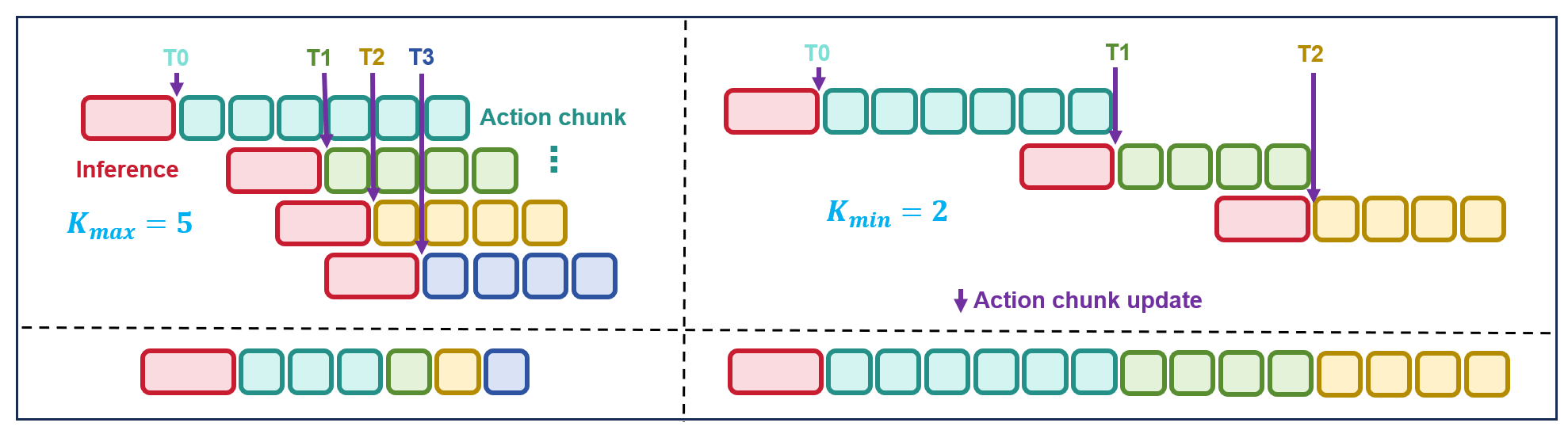
Flow-consistent inpainting
Flow-consistent inpainting enables next-chunk inference to overlap with current execution while preserving action continuity, supporting efficient real-world deployment on Jetson Orin NX.
Method Overview
CT-VAM targets low-level visuomotor execution and is designed for efficient closed-loop, onboard deployment. Given dual-view visual observations, proprioception, and the task condition, CT-VAM predicts action chunks for closed-loop execution.
TARS routes heterogeneous action, visual, proprioceptive, and task streams through a stream-separated conditional attention decoder.
Flow-Consistent Inpainting
Although a compact model reduces per-chunk inference latency, real-time manipulation still requires careful execution scheduling. Flow-consistent inpainting supports asynchronous chunk execution by decoding the next action chunk while the current chunk is being executed and constraining the overlap region to preserve action continuity.
LIBERO Benchmark
CT-VAM is evaluated on LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, and LIBERO-Long. The policy takes two visual observations, proprioceptive states, and a one-hot task identifier as input, without invoking a large VLM during low-level execution.
Method
Params
Spatial
Object
Goal
Long
Avg.
Policy With VLM
OpenVLA
7000M
84.7
88.4
79.2
53.7
76.5
SpatialVLA
4000M
88.2
89.9
78.6
55.5
78.1
π0-FAST
3300M
96.4
96.8
88.6
60.2
85.5
π0
3300M
90.0
86.0
95.0
73.0
86.0
Policy Without VLM
Diffusion Policy
--
78.3
92.5
68.3
50.5
72.4
MDT
~225M
78.5
87.5
73.5
64.8
76.1
CT-VAM (Ours)
68M
89.0
94.6
78.4
66.2
82.1
With only 68M parameters, CT-VAM achieves competitive overall performance and outperforms existing non-VLM baselines on average, while remaining much smaller than billion-scale VLM policies.
Real-World Experiments
CT-VAM is evaluated on two real-world tabletop manipulation tasks. Ball Pouring is used for quantitative comparison with baseline methods and ablated variants, while Box Opening and Placement is used to examine long-horizon task-conditioned execution under subtask switching.
Real-world experimental setup and task workflow: OpenArm platform, inference devices including Jetson Orin NX and NVIDIA RTX 4080, and representative execution sequences.
Method
RTX 4080
Jetson Orin NX
Success (%) ↑
Exec. Time (s) ↓
Infer. Time (ms) ↓
Success (%) ↑
Exec. Time (s) ↓
Infer. Time (ms) ↓
Diffusion Policy
70.0
27.21
303.27
N.T.
N.T.
N.T.
π0
95.0
7.82
117.24
N.D.
N.D.
N.D.
CT-VAM w/o FCI
100
8.33
56.32
85
10.24
256.24
CT-VAM w/ FCI
95
6.41
56.84
90
7.23
200.60
N.T. indicates that the method was not tested on Jetson Orin NX. N.D. indicates that the method could not be deployed due to memory constraints.
Task Visualizations
Ball pouring task: the robot grasps a bottle, adjusts its pose, and pours the contained balls into the target tray.
Box opening and placement task: the task is divided into three manually labeled subtasks during data collection and evaluation.
LIBERO benchmark results: representative task execution performance on LIBERO.
Comparison with Diffusion Policy, π0, and CT-VAM variants with/without flow-consistent inpainting (FCI).
Deployment comparison between RTX 4080 and Jetson Orin NX for real-world inference.
Long-horizon Box opening and placement execution with subtask switching.
FAQ
Why does the current implementation use one-hot task tokens instead of raw language instructions?
The current one-hot design is used to isolate the evaluation of the low-level visuomotor policy. In this setting, the compact task token provides the task intent, while CT-VAM can be tested for whether it can perform closed-loop visual-proprioceptive action generation under a given intent. This allows the current experiments to focus on the capability of the lower-level execution module, rather than mixing it with the quality of an upstream language grounding module. In future work, this one-hot task representation will be replaced by a more complete language-to-intent encoding module that maps raw instructions and scene context into task-relevant intent representations.
BibTeX
@misc{li2026ctvam,
title = {{CT-VAM}: A Cerebello-Thalamic-Inspired Vision-Action Model for Efficient Visuomotor Control},
author = {Li, Jiacheng and Guo, Yize and Guo, Jiabin and Liu, Qingchen and Qin, Jiahu},
year = {2026},
eprint = {2606.09572},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2606.09572},
note = {Jiacheng Li, Yize Guo, and Jiabin Guo contributed equally to this work.}
}
Acknowledgements
We thank all collaborators and lab members for their helpful discussions and support. We also thank the OpenArm team for providing the open-source robot design, based on which we built our own robotic platform. We are grateful to our advisor for valuable guidance. We especially thank Nanping Deng for strong support in experimental deployment, and Mingyu Liu for configuration support in deploying the algorithm on the Jetson Orin NX platform. We also thank Peidi Yang for helping collect a large amount of VR demonstration data.